邱晗:压力来临时金融科技风控模型的比较优势
2020-06-28
数字开放平台第四次学术论坛精彩发言(第五篇)
大数据与机器学习模型
邱晗
首先谢谢大家。这篇论文是和北京大学数字金融研究中心的黄益平教授、国际清算银行的经济学家Leonardo Gambacorta与北京大学数字金融研究中心特约研究员、中央财经大学金融学院王靖一老师一起完成的。这篇文章我们是想探究机器学习和非传统数据是怎么样影响信贷评分。这篇文章的数据来自于中国某头部金融科技公司的贷款数据。我们的文章分成六部分来展示。
第一部分是简单介绍文章的背景,我们为什么要做这篇文章。第二部分介绍这篇文章所使用的数据。因为数据的原因,让我们有一个比较好的切入点来探究问题。第三想介绍策略。第四个是介绍结果。第五个是稳健性检验。最后给初步的结论。
首先我们知道,各位老师也讲了,金融科技其实在各个方面都对我们整个金融体系有比较大的改变,包括之前讲的移动支付对消费的促进、财富效应等等。我们这篇文章,从信贷的角度切入。根据BIS在2019年的年报,金融科技在贷款角色当中起到了越来越重要的作用。当然会带来一些我们说的金融普惠,给一些以前缺少信息的企业做一个风险定价,提高公司的表现。这在很多的文献当中都已经有讨论了。我们就在思考一个问题,就是从信贷角度而言,金融科技有什么样的优势呢?第一点是信息的优势,第二点是模型的优势。很多文献都探讨了这个问题。比如说数据、数字足迹,可能使用什么样的类型的信息,app等,对我们的信用都是比较好的反应。包括像我们的蚂蚁金服,其实对小微企业的风险定价,包括network,都是非常好的数据,对传统的金融机构,比方说银行,数据较难获得。由此可以提高风险评价的水平。第二个是模型的优势。我们知道可能整个金融科技公司中大量的人员都是数据出身的,对于模型的理解可能更加深刻或者说使用的模型计算能力更强,可能在利用信息方面也有比传统银行要更加具有优势。所以我们可能这篇文章从这两个角度来切入这个问题。
从贡献上说,文章对文献进行了补充。基本上之前的文献都是在探讨我们这样的经济环境是平稳状态,所谓的机器学习或者非传统数据是可行的,很多证据都说明会有提升。但是如果经济环境发生了变化,在经济下行或者有压力的时候,这个方法是不是还是适用的。这很重要,一方面,从学术角度来说,是对一些金融危机的文献有一定的补充;另一方面,对监管来说,之前银监会李文红老师的文章也指出,金融科技的担忧是不是能在完整的金融周期当中有效。数据是在经济平稳期训练出来的。下行时是否能经受压力?如果不行,那么不能推广金融科技,会带来很大的损失。文章考虑了历史事件、探究金融科技模型,基于大数据、机器学习,是不是比其他模型更不稳定?
根据介绍,这篇文章想探讨四个问题。第一,简单总结一下模型的优势,是不是基于机器学习的模型要比传统线性logit模型,在预测借款人的违约或者是贷款损失上有更好的表现。第二是,我们这些信息,利用一些非传统信息,是否能在传统的基础上有增益作用。信息来源于两个。第一个是社交数据,例如和家人的联系。第二个是在电商平台上的购买数据,一些消费行为。第三个是我们想探究的如果现在外部有一个负面的冲击,不良率一下提升了很多,整个金融环境都变得比原来糟糕,这些模型表现会如何?最后,想探究金融科技模型的优势会不会随着客户和传统银行的关系不同而改变吗?比方这个人刚刚接触传统银行,或者已经有较长的信贷关系。对于不同种类的人群,金融科技的模型会有什么样的增益效果。
简单给一下文章目前初步发现的结果。第一,认为机器学习的方法以及利用一些传统数据是有助于提升模型的预测能力的,与文献相同。对于在压力测试,外部负面冲击情况下,所有的模型都会降低预测能力,但是相对来说,如果使用了更多的数据,机器学习模型下降的幅度会少一些。比传统的模型要更稳健。然后一点是,我们发现随着借款人和传统银行的关系不断增加,他的机器学习的增益程度是先增加后减少的。因为金融科技模型也可以使用传统信息。配合起来有一加一大于二的效果。但是到了一定程度,例如五年六年以后,银行已经足够了解借款人了,此时增益效果就会下降。
下面介绍一下文章使用的数据。文章使用了头部的中国的金融科技公司,2017年5月-2017年9月的贷款层面的数据,最长年限是24个月。我们有它发贷时的信息,还有每个月的还款记录,一直到2018年10月。我们获得金融科技分数,以及金融科技分数背后的变量的。这个分数是用自己的机器模型来和传统的变量相结合计算的。这家公司有很多变量。但是计算分数时,只用到几十个变量。所以我们在最后面的研究中,用到了相同的变量考虑的。
好处是,他们兼具了传统和非传统的信息,有详尽的信用卡数据。银行给客人利用信用卡做贷款的中小企业主,其主要依据就是非常详尽的信用卡数据。以及非传统数据。我们要说的是,尤其是对国外的文献,他们想讲述传统银行的客户经理和借款人之间建立了软信息,在我们这里是无法衡量的。金融科技公司没有这样的精力。这与以往的文献不同,因为以往是一些P2P相关的文献,有本人汇报财务信息,但我们这篇文章的数据都来自于这个人个人的、经过用户授权的、系统抓取的数据,其真实度是很高的。
这是统计描述。可以看到,是否违约和违约率同时是评价标准。之所以这样,是因为,一个人第一个月就违约和十二个月后违约,对于平台来说,损失是完全不同的。下一个是金融科技分数,然后是贷款利率。之后是传统的信息,例如银行账户、信用卡使用额度、信用卡最高额度(相当于银行对其的评价。中国的利率还没有完全放开,额度很能代表银行的评价)、和银行最早进行业务的时间等等,来衡量和银行的关系。除了这些传统变量,还有很多非传统变量,具体而言是一些社交数据和在电商平台上的购买数据。
实证策略是构建两个简单的模型。第一个是Tobit模型,第二个是Logit模型。每个模型中都含三个模型。第一个就是使用Fintech creditscoring代表金融科技的评分模式。第二个用传统的信息基于传统的方法。第三个模型用所有的信息,基于传统的方法。我们是想通过后两个模型的比较来看非传统信息的贡献。通过一和三的比较,来看方法上的不同贡献。因为一三的数据相同,只是方法不同。
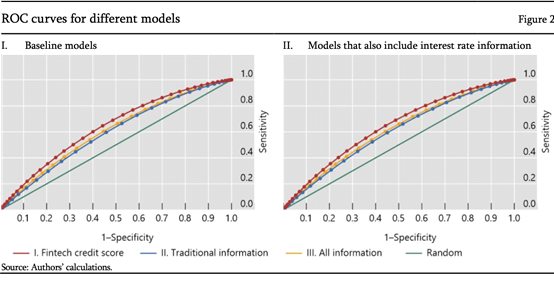
然后展示一些我们现在得到的结果。首先我们用一个经济学中用的非常多的评判指标来评价拟合度,即。对于Loss rate,使用金融科技的方式的明显大于后两者。但是对于二三来说,用了更多的信息,更大。对于Default rate也是一样的。初步的结果告诉我们,对于金融科技的分数,无论是预测Loss rate还是是否违约,都是有表现最好的。换一种方法来评价这三个模型。如果用ROC curve来评价的话。ROC curve的横坐标是所有不违约但是被判定为违约的,纵坐标是违约的人被判定成不违约的。我们可以想象,为什么这个指标比较合适?
其实我们在做风控的时候,大体上有两个步骤。第一个就是需要有一个策略,简单来说可能就是规定一个阈值,来决定是否要给这个人贷款。但是在这个模型里面,是没有去给定这个阈值的。原因其实是每种阈值的指标之间的关系。如果我把阈值定得很高,也就是可以接受所有的人来进行贷款,或者我把阈值定的特别低,任何人都不接受,其实是在坐标轴的(1,1)点和(0,0)点的。曲线越往上,证明模型效果是越好的。简单看一下,初步的结果是,红色的线是金融科技分数的模型评价,蓝色的线是传统的变量,黄色的线是所有的变量。可以发现,和之前展示的R方结果是类似的。金融科技分数更靠上,然后是黄色的所有的变量,最后是传统的变量。45度线是一个随机的,也就是说不使用模型的情况,随机决定是否贷款,也就是没有模型的情况。这之后,我们又加了利率。对于利率,我们非常小心。因为利率本身就是风控的结果。比方说高风险的高利率,低风险低利率。但这也可能影响违约。因为对于利率高的贷款,可能这个人更有意愿违约。所以还是放入了稳健性检验。后两个模型引入利率变量,结果是一致的。
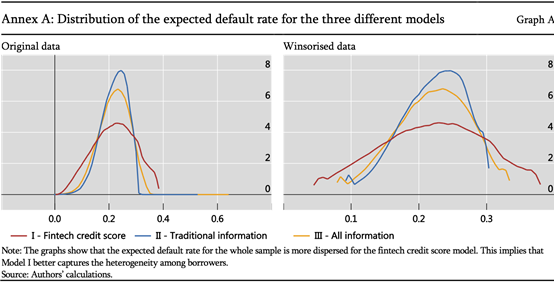
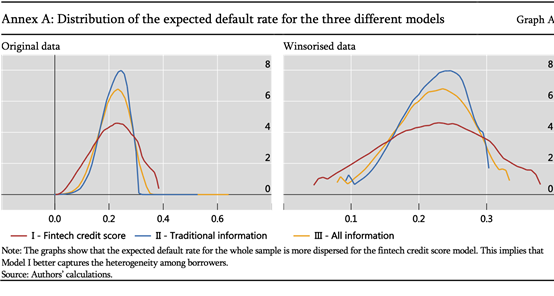
进一步,对AUC做了95分位数处理,因为从图像上来看,差别是存在的,但是不一定是显著有差别的。所以做了处理。发现三类模型的差别都是显著存在的。之后我们想看为什么金融科技的模型会表现更好。把分布图画出来,横坐标是预测的违约率,越高表示评级越差,反之越好。可以发现,结果不变。金融科技的红线分布图相对所有信息更好,又均好于传统信息。金融科技方法分布非常广,可以给很多用户有区分度的评价,把他们真正区分开来。但是另外两种的分布特别集中,会把很多人认为是一种或者类似的违约,无法很好地把很多人做很好的区分。这可能就是区分度的提高,使得金融科技的优势更大。为什么区分度高?可能是因为它使用了比较多的信息,这是第一点。第二点机器学习信息间的交互关系,从而评价所使用的指标是很多的,可以更精准的评价,区分度自然更高。这是我们的猜想。
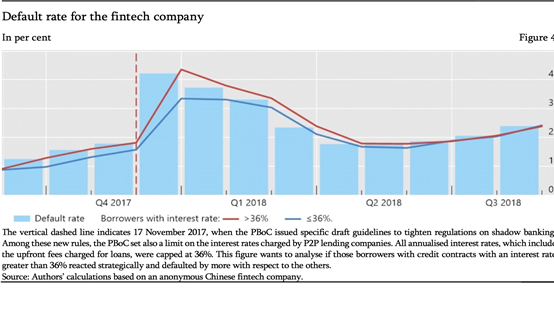
接下来,我们想看看在非平稳时期,比方说外界有负面的冲击来临的时候,这三种模型的表现是什么样的?这里正好可以找到资管新规的意见稿的出台。在2017年11月17日,对中国的金融体系影响特别大的一个政策出台了。其中包含了很多子政策,比方说针对金融科技等等。这个政策对中国的经济产生了较大的影响,金融条件也是一样的。中国的证据发现,在2017年年底,中国由于资管新规政策的发生,整个情况开始出现变化,违约率开始大幅度上升。对于平台来说,也是有影响的。进一步把每个人的违约月份数据调出来,蓝色的柱状图是贷款除以还未违约的贷款的比率,来计算其违约情况。发现在政策出台之前,违约率都是比较低的,但是出台后,违约率开始大幅度上升、持续性上升,足足四个月才减下来。可能该违约的都违约了才降下来。为了保证结果的稳健性,考虑更多。2019.12.1规定,贷款利率是36%以上的贷款,政策有非常强的抑制性影响。分成两部分考虑,第一是达到36%的利率,第二是没有达到的。结果两部分人群都有一个违约率的提升。所以非常强的抑制性影响可能是不存在的。即使有,也不是特别强。
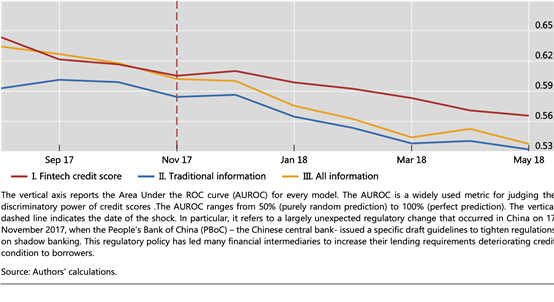
接下来是检验。已经得到了AUC,对每个人有了预测违约率,使用这个比率对数据在每个月进行排名,想看看是不是在每个月都会比较合理。如果在平稳时期预测比较合理,在压力测试中预测变得不合理,AUC就会大幅度下降。但是如果两种情况都比较稳定,AUC就不会有大幅度的下滑。我们做了这样的对比,发现对于三个模型的比较,在政策出来之后,长期来看都是在下滑的。但是相对来说代表金融科技的红线更加稳定一些,其他的则下滑幅度比较大。进一步,把它区分发现,在平稳时期,传统数据扮演重要作用,但是压力后,非传统数据贡献性就提升了。我们可能的解释是,因为我们使用了一些非传统信息,比方说社交数据等。这种数据可能在短时间之内,负面冲击发生后,一个人的行为是很难发生变的。所以如果加入了这些信息,更有利于模型的稳健性。第二个可能就是,机器学习探究了交互方法。对人群细致区分,发现其实当负面冲击来临时,越坏的人会更坏,好的人会变的糟糕,但也不会比坏人更糟糕。这时候模型更好的区分比没有这样做的模型来的更稳健。进一步绘图,直观地来看,负面冲击的影响。横坐标还是预期违约率,画出分布。把政策冲击之前两个月和之后两个月的样本找出来,做了分布图。可以看出,对于使用传统数据和所有信息的传统模型,红线说明在负面冲击发生后,分布变得左偏。意味着这部分人群原本更好。在这两种模型的评价体系下,更好的人开始违约了。在冲击前,是评价不好的人违约,冲击后,是评价好的人也违约了。说明这种模型的稳定性偏弱。但是对于金融科技模型,也是有一点左偏,但是相对来说变化并不明显。坏的人在之前之后都是差不多的。
接下来我们进行关于银行的关系的检验。使用人们第一次办信用卡的时间作为接触时间,根据样本等分成十份,画出了不同人群AUC的情况。从左图可以发现随着银行关系的加深,一开始增加的是所有信息模型或者金融科技模型。对于传统模型,提高的并不多。到后期,传统模型才会有提升。进一步差别化出来,右图和左图展示出来的情况是一样的。对于差别来说也是这样的。一开始也是随着时间的增加,AUC的差别是增加的,但是银行使用时间越长,差距又会不断变小了。这和我们原定假设不太一样。我们之前预测,银行的模型会越来越好。但是从证据来讲,一开始的时候,银行的信息还不足以支撑银行做特别好的风控,但是如果能够和非传统数据进行配合,可以带来一加一大于二的效果。但是过了一段时间,比如说过了在我们样本的中位数以后,银行可能已经有足够的信息来支撑了,金融科技模型的优势就会逐步减弱。
接下来做稳健性检验。刚刚用的样本期是5月到9月份的。如果换一个样本做,用其他的样本期来做序列,把模型代入到不同的时间,更加久远,比方2015-2016年。发现结果是保持稳健的。进一步我们做了一个其他的稳健性检验,是关于性别的。在很多国家,对于性别非常的重视。银行可能不能把它作为一个风控的标准。金融科技很多是使用了性别的。所以我们把性别的变量也放到传统模型中,发现结果也是一样的。
最后,给出一个简单的结论。第一,机器学习模型有增益的效果。第二,对于非传统的信息,可能可以提升模型的预测能力。第三,初步发现,在压力测试来临的时候,金融科技模型由于非传统信息的介入,表现更稳健,因为相对别的模型可以更好地刻画人的行为,虽然模型预测能力也会下降。第四,和银行的关系在传统数据刚刚积累的时候,金融科技模型的增益更大,一加一大于二;但随着和传统银行的关系越来越深,金融科技的优势会越来越弱。
文章的缺陷或不足。第一是只分析了一个资管新规出台这一个案例。虽然资管新规对中国产生了很大的影响,很多公司都是不良率大幅度增加的。但如果要得到稳健的结论可能需要更多案例的检验。第二是我们探究的主要是和传统银行的信用卡贷来比较,没有涉及银行其他类型的贷款数据(比如抵押贷款)。这是我的简单分享。
谢谢大家。
